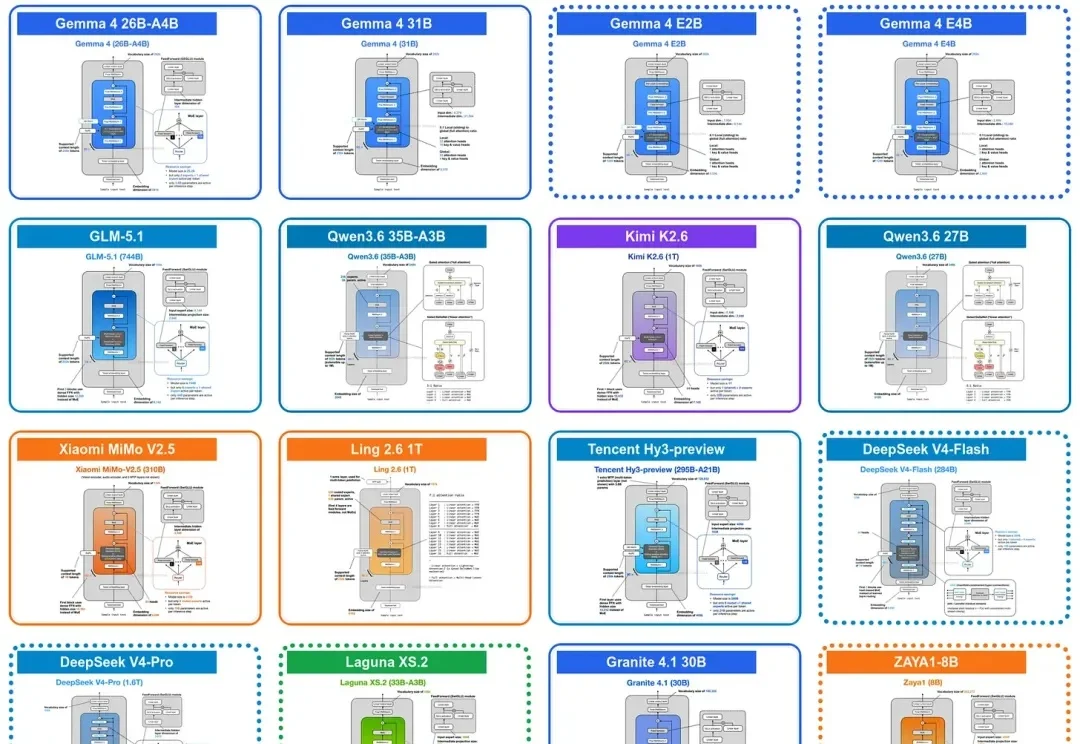
LLM近期重大架构进化一览:从Gemma 4到DeepSeek V4
LLM近期重大架构进化一览:从Gemma 4到DeepSeek V4过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。
来自主题: AI技术研报
7850 点击 2026-05-19 15:32
 搜索
搜索
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。
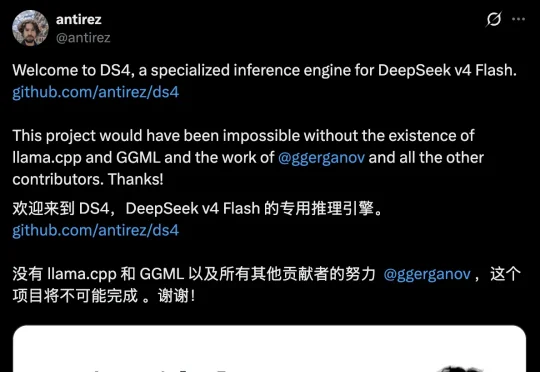
DeepSeek V4,已经开始逼着海外开发者为它修专属高速公路了。发布才两周,开源圈里,第一批V4原生基础设施已经冒了出来。它只干一件事:把DeepSeek V4 Flash,在Mac上跑到极致。这条“专属高速公路”,叫ds4.c。而把修出来的人,分量有点吓人——
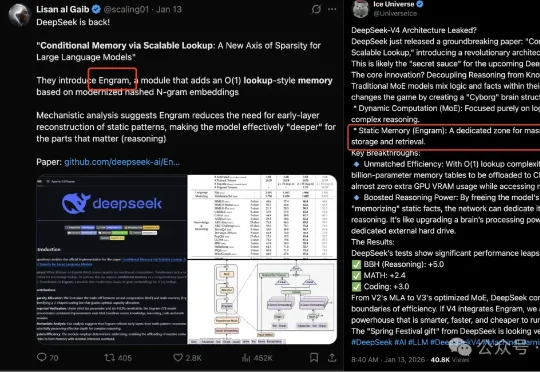
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。
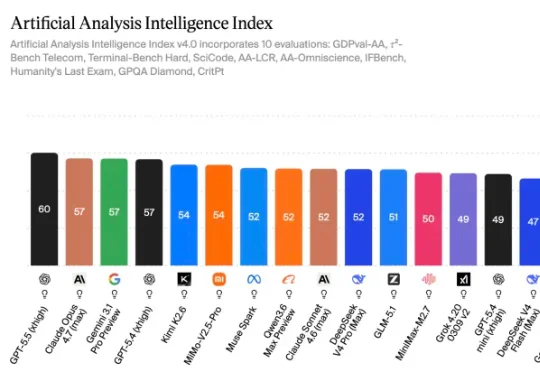
上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,记忆一样,skill一样,系统设置一样,能调用的工具也一样。

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。
四月真是如风驰电掣:Anthropic 发布了 Opus 4.7,OpenAI 发布了 GPT 5.5,最后,DeepSeek 更新了暌违已久的 V4。三家公司的发布通稿读起来都差不多:跑分又涨了,上下文更长了,推理更强了,代码能力又创了新高。
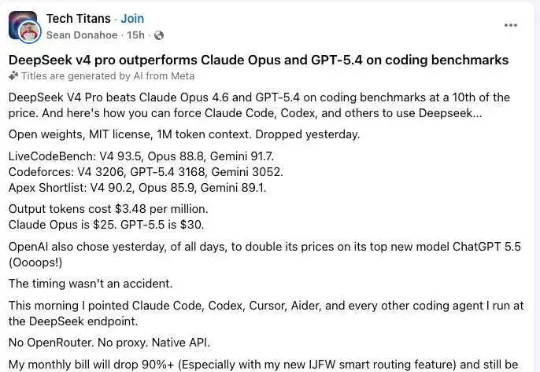
科技博主兼 AI 系统架构师 Sean Donahoe 在今天凌晨发了一条帖子。他写道:这条帖子实际上有两个看点。第一,发帖人是重度 AI 编程用户,却几乎一夜之间完成迁移,月账单会从几千美元降到几百美元。第二,他不只是说便宜,还强调效果没有变差,反而更好:“输出质量提高了,而不是下降,这一点已经通过内部测试以及多个公开基准验证”。

OpenClaw最新版本官宣,DeepSeek V4 Flash正式成为默认大模型,250k+星标的全球最火开源Agent框架,把中国最强开源AI推上了C位。

最新消息是,DeepSeek V4 Pro 2.5折的大力度优惠来啦!官方API文档显示,DeepSeek-V4-Pro模型API限时2.5折优惠,优惠期截至2026年5月5日。 具体是这样: 1️⃣百万tokens输入(缓存命中)折后0.25元(原价1元); 2️⃣百万tokens输入(缓存未命中)折后3元(原价12元); 3️⃣百万tokens输出折后6元(原价24元)。

今天上午,DeepSeek V4 发布,直接把这个大模型疯狂更新月推向了最高潮。不过在我翻看 V4 的技术报告的时候,在训练层面看到了一个被大部分人滑过去的名词:Muon 优化器。